SelfHostLLM
August 8, 2025•0 comments
Calculate GPU memory requirements and max concurrent requests for self-hosted LLM inference. Support for Llama, Qwen, DeepSeek, Mistral and more. Plan your AI infrastructure efficiently.
Project Images
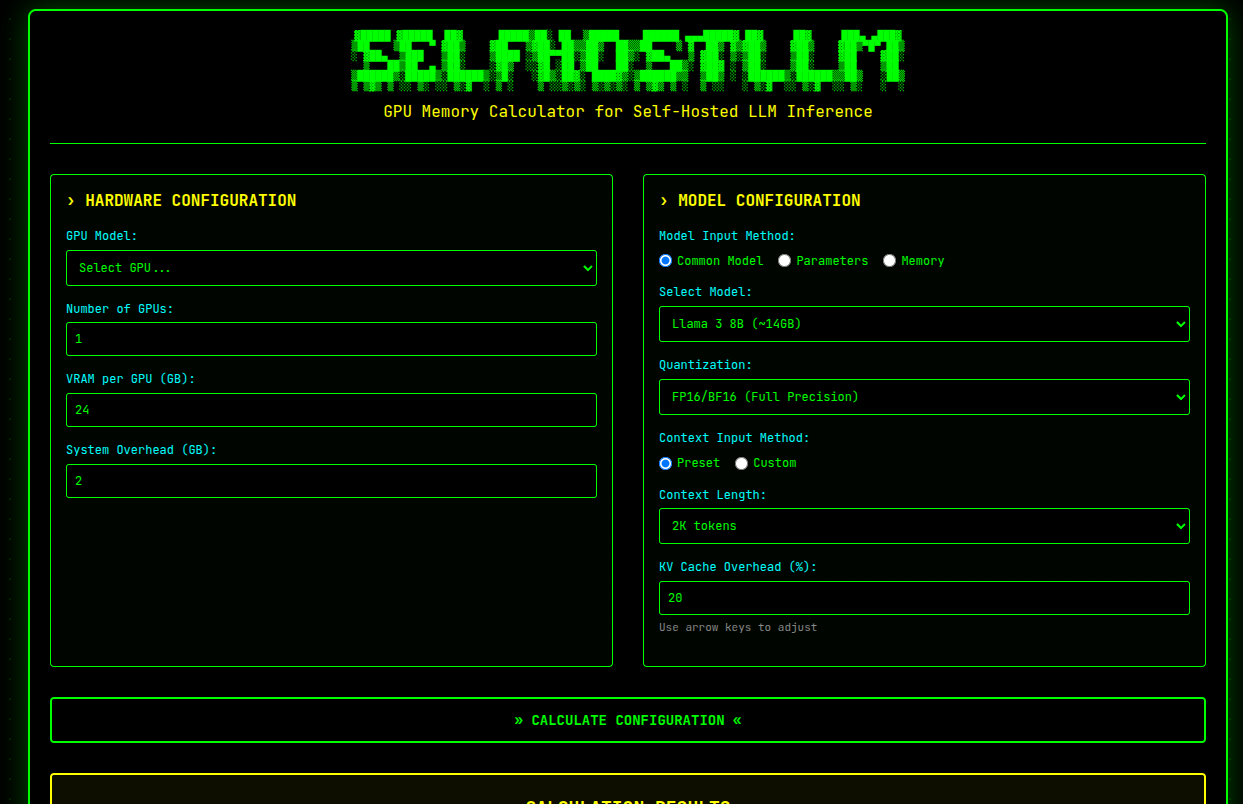
Calculate GPU memory requirements and max concurrent requests for self-hosted LLM inference. Support for Llama, Qwen, DeepSeek, Mistral and more. Plan your AI infrastructure efficiently.